OPERACIONALIZACION DE VARIABLES
Es
un proceso metodológico que consiste en descomponer deductivamente las
variables que componen el problema de investigación, partiendo desde lo más
general a lo más específico; es decir que estas variables se dividen (si son
complejas) en dimensiones, áreas, aspectos, indicadores, índices, subíndices,
ítems; mientras si son concretas solamente en indicadores, índices e ítems.
Ahora
bien, una variable es operacionalizada con la finalidad de convertir un
concepto abstracto en uno empírico, susceptible de ser medido a través de la
aplicación de un instrumento. Dicho proceso tiene su importancia en la
posibilidad que un investigador poco experimentado pueda tener la seguridad de
no perderse o cometer errores que son frecuentes en un proceso de investigación,
cuando no existe relación entre la variable y la forma en que se decidió medirla,
perdiendo así la validez, dicho de otro modo (grado en que la medición empírica
representa la medición conceptual). La precisión para definir los términos
tiene la ventaja de comunicar con exactitud los resultados.
En consecuencia, la operacionalización de las variables es el
proceso a través del cual el investigador explica en detalle la definición que
adoptará de las categorías y/o variables de estudio, tipos de valores (cuanti o
cualitativos) que podrían asumir las mismas y los cálculos que se tendrían que
realizar para obtener los valores de las variables cuantitativas. La
operacionalización es un proceso que variará de acuerdo al tipo de
investigación y de diseño. No obstante, las variables deben estar claramente
definidas y convenientemente operacionalizadas. Se consideran incompletos
aquellos protocolos cuyo nivel de operacionalización es muy vago.
Con fines didácticos explicamos cada una
de las columnas del cuadro que hacen parte del proceso de operacionalización de
una variable de estudio.
Variable
|
Tipo de Variable
|
Operacionalización
|
Categorización o Dimensiones
|
Definición
|
Indicador
|
Nivel de Medición
|
Unidad de Medida
|
Índice
|
Valor
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
J
|
A. Variable
·
Una variable es una característica que se va
a medir.
· Es una propiedad, un atributo que puede darse
o no en ciertos sujetos o fenómenos en estudio, así como también con menor o
mayor grado de representación en los mismos y por tanto con susceptibilidad de
medición.
·
Su misma palabra define que “debe permitir
rangos de variación”.
·
Es el conjunto de valores que constituyen una
clasificación.
· Debe traducirse del nivel conceptual
(abstracto) al nivel operativo (concreto), dicho de otra forma, que sea
observable y medible.
·
Se deriva de la unidad de análisis y están
contenidas en las hipótesis y en el título del estudio.
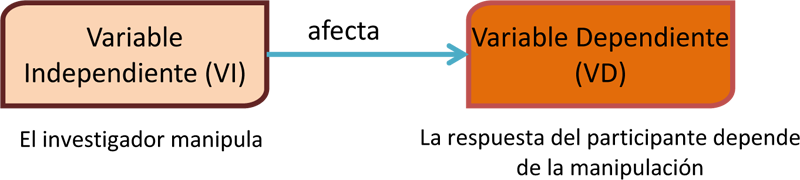
B. Tipo
de Variable
Hace
referencia a conceptos clasificatorios de las variables que puede ser de
distinto orden a saber:
Según
el nivel de medición: nominal, ordinal, de intervalo y de razón (se explican en
el numeral H).
Según el tipo de estudio: en
estudios de investigación donde se supone la determinación de una o más variables
sobre otra, las investigaciones son de relación causa-efecto, y en ellos las
variables son denominadas: independiente, que representa la causa eventual,
dependiente o de criterio, que representa el efecto posible, e interviniente
aquella que representa una tercera variable que actúa entre la independiente y
la dependiente y que puede ayudar a una mejor comprensión de dicha relación.
Según el origen de la variable:
activa, cuando el investigador la crea o la diseña y, atributiva o preexistente
cuando ya está establecida o existe.
Según el número de valores que
representa: continua, representa valores de manera
progresiva y admite fraccionamiento como la edad y, categórica o discreta
cuando sólo toma algunos valores discretos o sea que no admite fraccionamiento
tales como el género, la raza, el número de hijos o de embarazos; si la
variable sólo toma dos valores como el sexo se denomina categórica dicotómica,
pero si toma más de dos valores se denominará politómica.
Según el control de la variable por
parte del investigador: la variable que tiene efecto sobre la
variable dependiente requiere que sea controlada por el investigador, por
ejemplo, el número de cigarrillos que consume por día un fumador y su relación
con la aparición prematura de la patología pulmonar, en este caso la variable
se denomina controlable o controlada. Cuando en el diseño o en el análisis la
variable no se considera, será una variable no controlada.
C. Operacional
o definición operacional
Explica
cómo se define el concepto específicamente en el estudio planteado, que puede
diferir de su definición etimológica.
Equivale
a hacer que la variable sea mensurable a través de la concreción de su
significado, y está muy relacionada con una adecuada revisión de la literatura.
Puede
omitirse cuando la definición es obvia y compartida.
D. Categorización
o dimensiones
Cuando
el concepto tiene varias dimensiones o clasificaciones o categorías, éstas
deben especificarse en el estudio; tal es el caso de la variable recursos, que
puede hacer referencia a recursos técnicos, financieros, ambientales, humanos
entre otros.
E. Definición
de las categorías o dimensiones
Cada
una de las dimensiones, categorías o clasificaciones debe ser definida
conceptual y etimológicamente.
F. Indicador
Es
la señal que permite identificar las características de las variables. Se da
con respecto a un punto de referencia. Son señales comparativas con respecto a
contextos o a sí mismas.
Su expresión matemática se nutre de la estadística, la
epidemiología y la economía.
El
indicador tiene por función de señalar cómo medir cada uno de los factores o
rasgos de la variable.
·
Se expresa en razones, proporciones, tasas e
índices.
·
Permite hacer “medible” la variable.
Son
ejemplos de indicadores: indicadores económicos (el dólar estadounidense, un
kilo de café, una onza de plata).
Indicadores
de pobreza (las migraciones, los desplazamientos forzados, el desempleo, los
asentamientos humanos).
Indicadores
de calidad de vida (tasa de fecundidad, de esperanza de vida, de natalidad, de mortalidad).
Indicadores
de desarrollo (el PIB: producto bruto interno, la inflación, tasa de desempleo,
el IPC: índice de precios al consumidor). Así los indicadores pueden ser
construidos por el investigador.
G. Nivel
de medición
La
medición de una variable se refiere a su posibilidad de cuantificación o
cualificación, y éstas se clasifican según el nivel o capacidad en que permite
ser medido el objeto en estudio. Según el tipo de operaciones matemáticas que
se puedan realizar con los números asignados al medir la variable, se
distinguen cuatro niveles de medición estadística, como son:
·
Nominal
Este
nivel sólo permite clasificar, es decir, la única relación existente entre los
objetos a los cuales se les ha asignado un número es una relación de
equivalencia. Por ejemplo, si en el variable sexo se ha asignado el numeral 1
para designar a los hombres y el número 2, para referirse a las mujeres, quiere
decir que todos los miembros a los que se les asigne el numeral 1 son hombres,
o sea, tienen una condición equivalente. La relación de equivalencia es
reflexiva (a=a) , es simétrica (si a=b entonces b=a) y es transitiva (si a=b y
b=c entonces a=c), de acuerdo con estas propiedades las técnicas estadísticas
posibles de usar con la escala nominal son la moda y el cálculo de frecuencias
también se pueden usar medidas no paramétricas como el chi cuadrado y la
expresión binomial; en cuanto a medidas de asociación se puede usar el
coeficiente de contingencia, Es necesario recalcar que los números asignados a
las diferentes categorías de la variable cualitativa sirven para almacenamiento
de datos, pero por ser de asignación arbitraria no indica que se trate de
variables cuantitativas.
·
Ordinal
Permite
clasificar además ordenar, es decir, establecer una secuencia lógica que mide
la intensidad del atributo. Por ejemplo, al medir el grado de satisfacción
frente a un servicio de salud, se pueden establecer escalas tales como:
satisfacción plena, satisfacción media, poca satisfacción, o insatisfacción;
esta escala difiere de la meramente nominal que permite establecer un orden o
graduación entre las observaciones. Las técnicas estadísticas apropiadas para
las mediciones ordinales son: la mediana para describir las tendencias
centrales, los coeficientes de Spearman, de Kendall y Gamma, para correlaciones
y pruebas no paramétricas como Wilcoxon, Kolmorov-Smirnov, entre otras para
pruebas de hipótesis. Al igual que el nivel nominal, los números asignados sólo
indican un orden o rango entre los objetos y en ningún momento indican relación
numérica, tal como el ejemplo anterior si el grado de satisfacción plena se le
asigna el número 4 y 2 al grado de poca satisfacción, no indica esto que quien
marcó el número 4 esté el doble de satisfecho que quien marcó el número 2. La
escala ordinal además de poseer las propiedades de la relación de equivalencia
del nivel nominal posee también la relación mayor que, expresada en términos
como más satisfecho, más estable, de mayor tamaño, de mayor preferencia, más
peligroso, más útil, de mayor riesgo etcétera. Todas las escalas
socio-económicas pertenecen al nivel ordinal de medición, ya que las distancias
entre clases sociales o estratos económicos no son iguales, si lo fueran
pertenecerían al nivel intervalar.
·
Intervalar o Numérica
·
De Razón o Proporción
Posee
las propiedades anteriores como clasificar, ordenar; los intervalos son iguales
y además, existe el cero absoluto o verdadero”, lo que quiere decir que si un
objeto que se está midiendo tiene el valor cero, ese objeto no posee la
propiedad o atributo que se está midiendo. Esta escala constituye el nivel más
alto de medición y admite para su análisis estadístico todas las técnicas y
pruebas de los niveles anteriores, pero además admite la media geométrica, el
cálculo del coeficiente de variación y las pruebas que requieran del
conocimiento del punto cero de la escala.
NIVEL DE MEDICIÓN DE VARIABLES
ESCALA
|
TIPO DE VARIABLE
|
PROPIEDADES MATEMÁTICAS
|
PRUEBA ESTADÍSTICA
|
TÉCNICA ESTADÍSTICA
|
Nominal
|
Cualitativa Discreta
|
De equivalencia
|
No paramétrica
|
Moda cálculo de frecuencias, chi cuadrado,
expresión binomial, coeficiente de contingencia
|
Ordinal
|
Cualitativa Discreta
|
-De equivalencia
-Mayor que
|
No paramétrica
|
Las anteriores y se adiciona: la mediana (tendencia
central). Coeficientes de Spearman, Kendall, Gamma, Percentilles.
|
Intervalo
|
Cuantitativa Continua
|
-De equivalencia
-Mayor qué
-Razón entre dos intervalos calculable.
|
No paramétrica y paramétrica
|
Las anteriores y se adiciona: media aritmética,
desviación estándar, correlación de Pearson, correlación múltiple.
|
Razón o proporción
|
Cuantitativa Continua
|
-De equivalencia
-Mayor qué
-Razón entre dos intervalos calculable
-Razón entre dos valores de la escala calculable.
|
No paramétrica y paramétrica
|
Las anteriores y se adiciona: Media geométrica,
coeficiente de variación y otras.
|
H. Unidad
de medida
Se
refiere a la respuesta que se espera en la medición planeada.
Puede
ser cuantitativa: en kilos, en metros, en litros, en porcentajes, en
proporciones, en tasas. Puede ser cualitativa: en grados de satisfacción
(mucho, regular, poco), en calificaciones (excelente, regular, insuficiente),
en grado de acuerdo (si y no) o (muy de acuerdo, en acuerdo, en desacuerdo) etcétera.
I. Índice
Es
la expresión del indicador por ejemplo:
·
Índice ocupacional: porcentaje de camas
ocupadas.
·
Índice de desempleo: porcentaje de
desempleados.
·
Índice de transición demográfica: porcentaje
de atraso o avance de una sección del país.
J. Valor
Es
el resultado o número de resultados posibles que se obtiene de una variable.
Cuando una variable puede medirse a través de varios indicadores, algunos de
ellos pueden tener mayor valor que otros y por tanto se hace necesario
explicitarlo. Por ejemplo: la variable “calidad docente” puede medirse a través
de: la hoja de vida del docente, el grado de capacitación, o sea. El número de
títulos académicos, un examen de conocimientos o una prueba pedagógica: pero es
posible que se le asigne un mayor valor porcentual a la hoja de vida y al grado
de capacitación que a las dos restantes.